Выбор и описание хэш-функции
Для хэш-адресации с рехэшированием в качестве хэш-функции возьмем функцию, которая будет получать на входе строку, а в результате выдавать сумму кодов первого, среднего и последнего элементов строки. Причем если строка содержит менее трех символов, то один и тот же символ будет взят и в качестве первого, и в качестве среднего, и в качестве последнего.
Будем считать, что прописные и строчные буквы в идентификаторах различны. В качестве кодов символов возьмем коды таблицы ASCII, которая используется в вычислительных системах на базе ОС типа Microsoft Windows. Тогда, если положить, что строка из области определения хэш-функции содержит только цифры и буквы английского алфавита, то минимальным значением хэш-функции будет сумма трех кодов цифры "0", а максимальным значением – сумма трех кодов литеры "z".
Таким образом, область значений выбранной хэш-функции в терминах языка Object Pascal может быть описана как:
(Ord(0 )+Ord(0 )+Ord(0 ))..(Ord('z')+Ord('z')+Ord('z'))
Диапазон области значений составляет 223 элемента, что удовлетворяет требованиям задания (не менее 200 элементов). Длина входных идентификаторов в данном случае ничем не ограничена. Для удобства пользования опишем две константы, задающие границы области значений хэш-функции:
HASH_MIN = Ord(0 )+Ord(0 )+Ord(0 );
HASH_MAX = Ord('z')+Ord('z')+Ord('z').
Сама хэш-функция без учета рехэширования будет вычислять следующее выражение:
Ord(sName[1]) + Ord(sName[(Length(sName)+1) div 2]) + Ord(sName[Length(sName);
здесь sName – это входная строка (аргумент хэш-функции).
Для рехэширования возьмем простейший генератор последовательности псевдослучайных чисел, построенный на основе формулы F = i-H1 mod Н2, где Н1 и Н2 – простые числа, выбранные таким образом, чтобы H1 было в диапазоне от Н2/2 до Н2. Причем, чтобы этот генератор выдавал максимально длинную последовательность во всем диапазоне от HASH_MIN до HASH_MAX, Н2 должно быть максимально близко к величине HASH_MAX – HASН_МIN + 1. В данном случае диапазон содержит 223 элемента, и поскольку 223 – простое число, то возьмем Н2 = 223 (если бы размер диапазона не был простым числом, то в качестве Н2 нужно было бы взять ближайшее к нему меньшее простое число). В качестве H1 возьмем 127: H1 = 127.
Опишем соответствующие константы:
REHASH1 = 127;
REHASH2 = 223;
Тогда хэш-функция с учетом рехэширования будет иметь следующий вид:
function VarHash(const sName: string; iNum: integer):longint;
begin
Result:=(Ord(sName[1])+Ord(sName[(Length(sName)+1) div 2])
+ Ord(sName[Length(sName)]) – HASH_MIN
+ iNum*REHASH1 mod REHASH2)
mod (HASH_MAX-HASH_MIN+1) + HASH_MIN;
if Result < HASH_MIN then Result:= HASH_MIN;
end;
Входные параметры этой функции: sName – имя хэшируемого идентификатора, iNum – индекс рехэшированиея (если iNum = 0, то рехэширование отсутствует). Строка проверки величины результата (Result < HASH_MIN) добавлена, чтобы исключить ошибки в тех случаях, когда на вход функции подается строка, содержащая символы вне диапазона 0 ..'z' (поскольку контроль входных идентификаторов отсутствует, это имеет смысл).
Для комбинации хэш-адресации и бинарного дерева можно использовать более простую хэш-функцию – сумму кодов первого и среднего символов входной строки. Диапазон значений такой хэш-функции в терминах языка Object Pascal будет выглядеть так:
(Ord(0 )+Ord(0 ))..(Ord('z')+Ord('z'))
Этот диапазон содержит менее 200 элементов, однако функция будет удовлетворять требованиям задания, так как в комбинации с бинарным деревом она будет обеспечивать обработку неограниченного количества идентификаторов (максимальное количество идентификаторов будет ограничено только объемом доступной оперативной памяти компьютера).
Без применения рехэширования эта хэш-функция будет выглядеть значительно проще, чем описанная выше хэш-функция с учетом рехэширования:
function VarHash(const sName: string): longint;
begin
Result:=(Ord(sName[1])+Ord(sName[(Length(sName)+1) div 2])
– HASH_MIN) mod (HASH_MAX-HASH_MIN+1) + HASH_MIN;
if Result < HASH_MIN then Result:= HASH_MIN;
end.
Описание структур данных таблиц идентификаторов
В первую очередь необходимо описать структуру данных, которая будет использована для хранения информации об идентификаторах в таблицах идентификаторов. Для обеих таблиц (с рехэшированием на основе генератора псевдослучайных чисел и в комбинации с бинарным деревом) будем использовать одну и ту же структуру. В этом случае в таблицах будут храниться неиспользуемые данные, но программный код будет проще. В качестве учебного примера такой подход оправдан.
Структура данных таблицы идентификаторов (назовем ее TVarInfo) должна содержать в обязательном порядке поле имени идентификатора (поле sName: string), а также поля дополнительной информации об идентификаторе по усмотрению разработчиков компилятора. В лабораторной работе не предусмотрено хранение какой-либо дополнительной информации об идентификаторах, поэтому в качестве иллюстрации информационного поля включим в структуру TVarInfo дополнительную информационную структуру TAddVarInfo (поле pInfo: TAddVarInfo).
Поскольку в языке Object Pascal для полей и переменных, описанных как class, хранятся только ссылки на соответствующую структуру, такой подход не приведет к значительным расходам памяти, но позволит в будущем хранить любую информацию, связанную с идентификатором, в отдельной структуре данных (поскольку предполагается использовать создаваемые программные модули в последующих лабораторных работах). В данном случае другой подход невозможен, так как заранее не известно, какие данные необходимо будет хранить в таблицах идентификаторов. Но разработчик реального компилятора, как правило, знает, какую информацию требуется хранить, и может использовать другой подход – непосредственно включить все необходимые поля в структуру данных таблицы идентификаторов (в данном случае – в структуру TVarInfo) без использования промежуточных структур данных и ссылок.
Первый подход, реализованный в данном примере, обеспечивает более экономное использование оперативной памяти, но является более сложным и требует работы с динамическими структурами, второй подход более прост в реализации, но менее экономно использует память. Какой из двух подходов выбрать, решает разработчик компилятора в каждом конкретном случае (второй подход будет проиллюстрирован позже в примере к лабораторной работе № 4).
Для работы со структурой данных TVarInfo потребуются следующие функции:
• функции создания структуры данных и освобождения занимаемой памяти – реализованы как constructor Create и destructor Destroy;
• функции доступа к дополнительной информации – в данной реализации это procedure SetInfo и procedure ClearInfo.
Эти функции будут общими для таблицы идентификаторов с рехэшированием и для комбинированной таблицы идентификаторов.
Однако для комбинированной таблицы идентификаторов в структуру данных TVarInfo потребуется также включить дополнительные поля данных и функции, обеспечивающие организацию бинарного дерева:
• ссылки на левую ("меньшую") и правую ("большую") ветвь дерева – реализованы как поля данных minEl, maxEl: TVarInfo;
• функции добавления элемента в дерево – function AddElCnt и function AddElem;
• функции поиска элемента в дереве – function FindElCnt и function FindElem;
• функция очистки информационных полей во всем дереве – procedure ClearAllInfo;
• функция вывода содержимого бинарного дерева в одну строку (для получения списка всех идентификаторов) – function GetElList.
Функции поиска и размещения элемента в дереве реализованы в двух экземплярах, так как одна из них выполняет подсчет количества сравнений, а другая – нет.
Поскольку на функции и процедуры не расходуется оперативная память, в результате получилось, что при использовании одной и той же структуры данных для разных таблиц идентификаторов в таблице с рехэшированием будет расходоваться неиспользуемая память только на хранение двух лишних ссылок (minEl и maxEl).
Полностью вся структура данных TVarInfo и связанные с ней процедуры и функции описаны в программном модуле TblElem. Полный текст этого программного модуля приведен в листинге П3.1 в приложении 3.
Надо обратить внимание на один важный момент в реализации функции поиска идентификатора в дереве (function TVarInfo.FindElCnt). Если выполнять сравнение двух строк (в данном случае – имени искомого идентификатора sN и имени идентификатора в текущем узле дерева sName) с помощью стандартных методов сравнения строк языка Object Pascal, то фрагмент программного кода выглядел бы примерно так:
if sN < sName then
begin
…
end
else
if sN > sName then
begin
…
end
else…
В этом фрагменте сравнение строк выполняется дважды: сначала проверяется отношение "меньше" (sN < sName), а потом – "больше" (sN > sName). И хотя в программном коде явно это не указано, для каждого из этих операторов будет вызвана библиотечная функция сравнения строк (то есть операция сравнения может выполниться дважды!). Чтобы этого избежать, в реализации предложенной в примере выполняется явный вызов функции сравнения строк, а потом обрабатывается полученный результат:
i:= StrComp(PChar(sN), PChar(sName));
if i < 0 then
begin
…
end
else
if i > 0 then
begin
…
end
else…
В таком варианте дважды может быть выполнено только сравнение целого числа с нулем, а сравнение строк всегда выполняется только один раз, что существенно увеличивает эффективность процедуры поиска.
Организация таблиц идентификаторов
Таблицы идентификаторов реализованы в виде статических массивов размером HASH_MIN..HASH_MAX, элементами которых являются структуры данных типа TVarInfo. В языке Object Pascal, как было сказано выше, для структур таких типов хранятся ссылки. Поэтому для обозначения пустых ячеек в таблицах идентификаторов будет использоваться пустая ссылка – nil.
Поскольку в памяти хранятся ссылки, описанные массивы будут играть роль хэш-таблиц, ссылки из которых указывают непосредственно на информацию в таблицах идентификаторов.
На рис. 1.3 показаны условные схемы, наглядно иллюстрирующие организацию таблиц идентификаторов. Схема 1 иллюстрирует таблицу идентификаторов с рехэшированием на основе генератора псевдослучайных чисел, схема 2 – таблицу идентификаторов на основе комбинации хэш-адресации с бинарным деревом. Ячейки с надписью "nil" соответствуют незаполненным ячейкам хэш-таблицы.
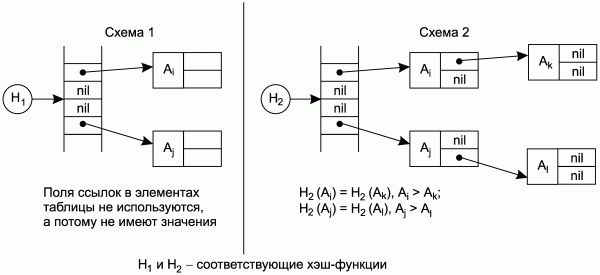
Рис. 1.3. Схемы организации таблиц идентификаторов.
Для каждой таблицы идентификаторов реализованы следующие функции:
• функции начальной инициализации хэш-таблицы – InitTreeVar и InitHashVar;
• функции освобождения памяти хэш-таблицы – ClearTreeVar и ClearHashVar;
• функции удаления дополнительной информации в таблице – ClearTreeInfo и ClearHashInfo;
• функции добавления элемента в таблицу идентификаторов – AddTreeVar и AddHashVar;
• функции поиска элемента в таблице идентификаторов – GetTreeVar и GetHashVar;
• функции, возвращающие количество выполненных операций сравнения при размещении или поиске элемента в таблице – GetTreeCount и GetHashCount.
Алгоритмы поиска и размещения идентификаторов для двух данных методов организации таблиц были описаны выше в разделе "Краткие теоретические сведения", поэтому приводить их здесь повторно нет смысла. Они реализованы в виде четырех перечисленных выше функций (AddTreeVar и AddHashVar – для размещения элемента; GetTreeVar и GetHashVar – для поиска элемента). Функции поиска и размещения элементов в таблице в качестве результата возвращают ссылку на элемент таблицы (структура которого описана в модуле TblElem) в случае успешного выполнения и нулевую ссылку – в противном случае.
Надо отметить, что функции размещения идентификатора в таблице организованы таким образом, что если на момент помещения нового идентификатора в таблице уже есть идентификатор с таким же именем, то функция не добавляет новый идентификатор в таблицу, а возвращает в качестве результата ссылку на ранее помещенный в таблицу идентификатор. Таким образом, в таблице не может быть двух и более идентификаторов с одинаковым именем. При этом наличие одинаковых идентификаторов во входном файле не воспринимается как ошибка – это допустимо, так как в задании не предусмотрено ограничение на наличие совпадающих имен идентификаторов.
Все перечисленные функции описаны в двух программных модулях: FncHash – для таблицы идентификаторов, построенной на основе рехэширования с использованием генератора псевдослучайных чисел, и FncTree – для таблицы идентификаторов, построенной на основе комбинации хэш-адресации и бинарного дерева. Кроме массивов данных для организации таблиц идентификаторов и функций работы с ними эти модули содержат также описание переменных, используемых для подсчета количества выполненных операций сравнения при размещении и поиске идентификатора в таблицах.
Полные тексты обоих модулей (FncHash и FncTree) можно найти на веб-сайте издательства, в файлах FncHash.pas и FncTree.pas. Кроме того, текст модуля FncTree приведен в листинге П3.2 в приложении 3.
Хочется обратить внимание на то, что в разделах инициализации (initialization) обоих модулей вызывается функция начального заполнения таблицы идентификаторов, а в разделах завершения (finalization) обоих модулей – функция освобождения памяти. Это гарантирует корректную работу модулей при любом порядке вызова остальных функций, поскольку Object Pascal сам обеспечивает своевременный вызов программного кода в разделах инициализации и завершения модулей.
Текст программы
Кроме перечисленных выше модулей необходим еще модуль, обеспечивающий интерфейс с пользователем. Этот модуль (FormLab1) реализует графическое окно TLab1Form на основе класса TForm библиотеки VCL. Он обеспечивает интерфейс средствами Graphical User Interface (GUI) в ОС типа Windows на основе стандартных органов управления из системных библиотек данной ОС. Кроме программного кода (файл FormLab1.pas) модуль включает в себя описание ресурсов пользовательского интерфейса (файл FormLab1.dfm). Более подробно принципы организации пользовательского интерфейса на основе GUI и работа систем программирования с ресурсами интерфейса описаны в [3, 5, 6, 7].
Кроме описания интерфейсной формы и ее органов управления модуль FormLab1 содержит три переменные (iCountNum, iCountHash, iCountTree), служащие для накопления статистических результатов по мере выполнения размещения и поиска идентификаторов в таблицах, а также функцию (procedure ViewStatistic) для отображения накопленной статистической информации на экране.
Интерфейсная форма, описанная в модуле, содержит следующие основные органы управления:
• поле ввода имени файла (EditFile), кнопка выбора имени файла из каталогов файловой системы (BtnFile), кнопка чтения файла (BtnLoad);
• многострочное поле для отображения прочитанного файла (Listldents);
• поле ввода имени искомого идентификатора (EditSearch);
• кнопка для поиска введенного идентификатора (BtnSearch) – этой кнопкой однократно вызывается процедура поиска (procedure SearchStr);
• кнопка автоматического поиска всех идентификаторов (BtnAllSearch) – этой кнопкой процедура поиска идентификатора (procedure SearchStr) вызывается циклически для всех считанных из файла идентификаторов (для всех, перечисленных в поле Listldents);
• кнопка сброса накопленной статистической информации (BtnReset);
• поля для отображения статистической информации;
• кнопка завершения работы с программой (BtnExit).
Внешний вид этой формы приведен на рис. 1.4.