В чисто объектно-ориентированных языках, таких как Smalltalk, операции могут быть только методами, так как процедуры и функции вне классов в этом языке определять не допускается. Напротив, в языках Object Pascal, C++, CLOS и Ada допускается описывать операции как независимые от объектов подпрограммы. В C++ они называются функциями-нечленами; мы же будем здесь называть их свободными подпрограммами. Свободные подпрограммы - это процедуры и функции, которые выполняют роль операций высокого уровня над объектом или объектами одного или разных классов. Свободные процедуры группируются в соответствии с классами, для которых они создаются. Это дает основание называть такие пакеты процедур утилитами класса. Например, для определенного выше класса Queue можно написать следующую свободную процедуру:
void copyUntilFound(Queue& from, Queue& to, void* item) {
while ((!from.isEmpty()) && (from.front() != item)) {
to.append(from.front()); from.pop();
}
}
Смысл в том, что содержимое одной очереди переходит в другую до тех пор, пока в голове первой очереди не окажется заданный объект. Это операция высокого уровня; она строится на операциях-примитивах класса Queue.
В C++ (и Smalltalk) принято собирать все логически связанные свободные подпрограммы и объявлять их частью некоторого класса, не имеющего состояния. Все такие функции будут статическими.
Таким образом, можно утверждать, что все методы - операции, но не все операции - методы: некоторые из них представляют собой свободные подпрограммы. Мы склонны использовать только методы, хотя, как будет показано в следующем разделе, иногда трудно удержаться от искушения, особенно если операция по своей природе выполняется над несколькими объектами разных классов и нет никаких причин объявить ее операцией именно одного класса, а не другого.
Роли и ответственности. Совокупность всех методов и свободных процедур, относящихся к конкретному объекту, образует протокол этого объекта. Протокол, таким образом, определяет поведение объекта, охватывающее все его статические и динамические аспекты. В самых нетривиальных абстракциях полезно подразделять протокол на частные аспекты поведения, которые мы будет называть ролями. Адамс говорит, что роль - это маска, которую носит объект [8]; она определяет контракт абстракции с ее клиентами.
Объединяя наши определения состояния и поведения объекта, Вирфс-Брок вводит понятие ответственности. "Ответственности объекта имеют две стороны - знания, которые объект поддерживает, и действия, которые объект может исполнить. Они выражают смысл его предназначения и место в системе. Ответственность понимается как совокупность всех услуг и всех контрактных обязательств объекта" [9]. Таким образом можно сказать, что состояние и поведение объекта определяют исполняемые им роли, а те, в свою очередь, необходимы для выполнения ответственности данной абстракции.
Действительно большинство интересных объектов исполняют в своей жизни разные роли, например [10]:
• Банковский счет может быть в хорошем или плохом состоянии (две роли), и от этой роли зависит, что произойдет при попытке снятия с него денег.
• Для фондового брокера пакет акций - это товар, который можно покупать или продавать, а для юриста это знак обладания определенными правами.
• В течении дня одна и та же персона может играть роль матери, врача, садовника и кинокритика.
Роли банковского счета являются динамическими и взаимоисключающими. Роли пакета акций слегка перекрываются, но каждая из них зависит от того, что клиент с ними делает. В случае персоны роли динамически изменяются каждую минуту.
Как мы увидим в главах 4 и 6, мы часто начинаем наш анализ с перечисления разных ролей, которые может играть объект. Во время проектирования мы выделяем эти роли, вводя конкретные операции, выполняющие ответственности каждой роли.
Объекты как автоматы. Наличие внутреннего состояния объектов означает, что порядок выполнения операций имеет существенное значение. Это наводит на мысль представить объект в качестве маленькой независимой машины [11]. Действительно, для ряда объектов такой временной порядок настолько существен, что наилучшим способом их формального описания будет конечный автомат. В главе 5 мы введем обозначения для описания иерархических конечных автоматов, которые можно использовать для выражения соответствующей семантики.
Продолжая аналогию с машинами, можно сказать, что объекты могут быть активными и пассивными. Активный объект имеет свой поток управления, а пассивный - нет. Активный объект в общем случае автономен, то есть он может проявлять свое поведение без воздействия со стороны других объектов. Пассивный объект, напротив, может изменять свое состояние только под воздействием других объектов. Таким образом, активные объекты системы - источники управляющих воздействий. Если система имеет несколько потоков управления, то и активных объектов может быть несколько. В последовательных системах обычно в каждый момент времени существует только один активный объект, например, главное окно, диспетчер которого ловит и обрабатывает все сообщения. В таком случае остальные объекты пассивны: их поведение проявляется, когда к ним обращается активный объект. В других видах последовательных архитектур (системы обработки транзакций) нет явного центра активности, и управление распределено среди пассивных объектов системы.
Идентичность
Семантика. Хошафян и Коуплэнд предложили следующее определение:
"Идентичность - это такое свойство объекта, которое отличает его от всех других объектов" [12].
Они отмечают, что "в большинстве языков программирования и управления базами данных для различения временных объектов их именуют, тем самым путая адресуемость и идентичность. Большинство баз данных различают постоянные объекты по ключевому атрибуту, тем самым смешивая идентичность и значение данных". Источником множества ошибок в объектно-ориентированном программировании является неумение отличать имя объекта от самого объекта.
Примеры. Начнем с определения точки на плоскости.
struct Point {
int x; int y; Point() : x(0), y(0) {} Point(int xValue, int yValue) : x(xValue), y(yValue) {)
};
Мы определили point как структуру, а не как полноценный класс. Правило, на основании которого мы так поступили, очень просто. Если абстракция представляет собой собрание других объектов без какого-либо собственного поведения, мы делаем ее структурой. Однако, когда наша абстракция подразумевает более сложное поведение, чем простой доступ к полям структуры, то нужно определять класс. В данном случае абстракция point - это просто пара координат (x, y). Для удобства предусмотрено два конструктора: один инициализирует точку нулевыми значениями координат, а другой - некоторыми заданными значениями.
Теперь определим экранный объект (DisplayItem). Это абстракция довольно обычна для систем с графическим интерфейсом (GUI) - она является базовым классом для всех объектов, которые можно отображать в окне. Мы хотим сделать его чем-то большим, чем просто совокупностью точек. Надо, чтобы клиенты могли рисовать, выбирать объекты и перемещать их по экрану, а также запрашивать их положение и состояние. Мы записываем нашу абстракцию в виде следующего объявления на C++:
class DisplayItem { public:
DisplayItem(); DisplayItem(const Point& location); virtual ~DisplayItem(); virtual void draw(); virtual void erase(); virtual void select(); virtual void unselect(); virtual void move(const Point& location); int isSelected() const; Point location() const; int isUnder(const Point& location) const;
protected: ... };
В этом объявлении мы намеренно опустили конструкторы, а также операторы для копирования, присваивания и проверки на равенство. Их мы оставим до следующего раздела.
Мы ожидаем, что у этого класса будет много наследников, поэтому деструктор и все модификаторы объявлены виртуальными. В особенности это относится к draw. Напротив, селекторы скорее всего не будут переопределяться в подклассах. Заметьте, что один из них, isUnder, должен вычислять, накрывает ли объект данную точку, а не просто возвращать значение какого-то свойства.
Объявим экземпляры указанных классов:
DisplayItem item1; DisplayItem* item2 = new DisplayItem(Point(75, 75)); DisplayItem* item3 = new DisplayItem(Point(100, 100)); DisplayItem* item4 = 0;
Рис. 3-1а показывает, что при выполнении этих операторов возникают четыре имени и три разных объекта. Конкретно, в памяти будут отведены четыре места под имена item1, item2, item3, item4. При этом item1 будет именем объекта класса DisplayItem, а три других будут указателями. Кроме того, лишь item2 и item3 будут на самом деле указывать на объекты класса DisplayItem. У объектов, на которые указывают item2 и item3, к тому же нет имен, хотя на них можно ссылаться "разыменовывая" соответствующие указатели: например, *item2. Поэтому мы можем сказать, что item2 указывает на отдельный объект класса DisplayItem, на имя которого мы можем косвенно ссылаться через *item2. Уникальная идентичность (но не обязательно имя) каждого объекта сохраняется на все время его существования, даже если его внутреннее состояние изменилось. Эта ситуация напоминает парадокс Зенона о реке: может ли река быть той же самый, если в ней каждый день течет разная вода?
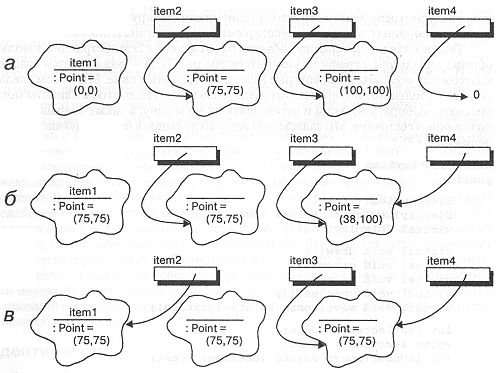
Рис. 3-1. Идентичность объектов.
Рассмотрим результат выполнения следующих операторов (рис. 3-1б):
item1.move(item2->location()); item4 = item3; item4->move(Point(38, 100));
Объект item1 и объект, на который указывает item2, теперь относятся к одной и той же точке экрана. Указатель item4 стал указывать на тот же объект, что и item3. Кстати, заметьте разницу между выражениями "объект item2" и "объект, на который указывает item2". Второе выражение более точно, хотя для краткости мы часто будем использовать их как синонимы.
Хотя объект item1 и объект, на который указывает item2, имеют одинаковое состояние, они остаются разными объектами. Кроме того, мы изменили состояние объекта *item3, использовав его новое косвенное имя item4. Эта ситуация, которую мы называем структурной зависимостью, подразумевая под этим ситуацию, когда объект именуется более чем одним способом несколькими синонимичными именами. Структурная зависимость порождает в объектно-ориентированном программировании много проблем. Трудность распознания побочных эффектов при действиях с синонимичными объектами часто приводит к "утечкам памяти", неправильному доступу к памяти, и, хуже того, непрогнозируемому изменению состояния. Например, если мы уничтожим объект через указатель item3, то значение указателя item4 окажется бессмысленным; эта ситуация называется повисшей ссылкой. На рис. 3-1в иллюстрируется результат выполнения следующих действий:
item2 = &item1; item4->move(item2->location());
В первой строке создается синоним: item2 указывает на тот же объект, что и item1. Во второй доступ к состоянию item1 получен через этот новый синоним. К сожалению, при этом произошла утечка памяти, - объект, на который первоначально указывала ссылка item2, никак не именуется ни прямо, ни косвенно, и его идентичность потеряна. В Smalltalk и CLOS память, отведенная под объекты, будет вновь возвращена системе сборщиком мусора. В языках типа C++ такая память не освобождается, пока не завершится программа, создавшая объект. Такие утечки памяти могут вызвать и просто неудобство, и крупные сбои, особенно, если программа должна непрерывно работать длительное время [Представьте себе утечку памяти в программе управления спутником или сердечным стимулятором. Перезапуск компьютера на спутнике в нескольких миллионах километров от Земли очень неудобен. Аналогично, непредсказуемая сборка мусора в программе, управляющей стимулятором, может оказаться смертельным для пациента. В таких случаях разработчики систем реального времени предпочитают воздерживаться от динамического распределения памяти].
Копирование, присваивание и равенство. Структурная зависимость имеет место, когда объект имеет несколько имен. В наиболее интересных приложениях объектно-ориентированного подхода использование синонимов просто неизбежно. Например, рассмотрим следующие две функции:
void highLight(DisplayItem& i); void drag(DisplayItem i); // Опасно
Если вызвать первую функцию с параметром item1, будет создан псевдоним: формальный параметр i означает указатель на фактический параметр, и следовательно item1 и i именуют один и тот же объект во время выполнения функции. При вызове второй функции с аргументом item1 ей передается новый объект, являющийся копией item1: i обозначает совершенно другой объект, хотя и с тем же состоянием, что и item1. В C++ различается передача параметров по ссылке и по значению. Надо следить за этим, иначе можно нечаянно изменить копию объекта, желая изменить сам объект [В Smalltalk семантика передачи объектов методам в качестве аргументов является по своему духу эквивалентом передачи параметра по ссылке в C++]. Как мы увидим в следующем разделе, передача объектов по ссылке в C++ необходима для программирования полиморфного поведения. В общем случае, передача объектов по ссылке крайне желательна для достаточно сложных объектов, поскольку при этом копируется ссылка, а не состояние, и следовательно, достигается большая эффективность (за исключением тех случаев, когда передаваемое значение очень простое).
В некоторых обстоятельствах, однако, подразумевается именно копирование. В языках типа C++ семантику копирования можно контролировать. В частности, мы можем ввести копирующий конструктор в определение класса, как в следующем фрагменте кода, который можно было бы включить в описание класса DisplayItem:
DisplayItem(const DisplayItem&);
В C++ копирующий конструктор может быть вызван явно (как часть описания объекта) или неявно (с передачей объекта по значению). Отсутствие этого специального конструктора вызывает копирующий конструктор, действующий по умолчанию, который копирует объект поэлементно. Однако, когда объект содержит ссылки или указатели на другие объекты, такая операция приводит к созданию синонимов указателей на объекты, что делает поэлементное копирование опасным. Мы предлагаем эмпирическое правило: разрешать неявное размножение путем копирования только для объектов, содержащих исключительно примитивные значения, и делать его явным для более сложных объектов.
Это правило поясняет то, что некоторые языки называют "поверхностным" и "глубоким" копированием. Чтобы копировать объект, в языке Smalltalk введены методы shallowCopy (метод копирует только объект, а состояние является разделяемым) и deepCopy (метод копирует объект и состояние, если нужно - рекурсивно). Переопределяя эти методы для классов с агрегацией, можно добиваться эффекта "глубокого" копирования для одних частей объекта, и "поверхностного" копирования остальных частей.
Присваивание - это, вообще говоря, копирование. В C++ его смысл тоже можно изменять. Например, мы могли бы добавить в определение класса DisplayItem следующую строку:
virtual DisplayItem& operator=(const DisplayItem&);
Этот оператор намеренно сделан виртуальным, так как ожидается, что подклассы будут его переопределять. Как и в случае копирующего конструктора, копирование можно сделать "глубоким" и "поверхностным". Если оператор присваивания не переопределен явно, то по умолчанию объект копируется поэлементно.
С вопросом присваивания тесно связан вопрос равенства. Хотя вопрос кажется простым, равенство можно понимать двумя способами. Во-первых, два имени могут обозначать один и тот же объект. Во-вторых, это может быть равенство состояний у двух разных объектов. В примере на рис. 3-1в оба варианта тождественности будут справедливы для item1 и item2. Однако для item2 и item3 истинным будет только второй вариант.
В C++ нет предопределенного оператора равенства, поэтому мы должны определить равенство и неравенство, объявив эти операторы при описании:
virtual int operator=(const DisplayItem&) const; int operator!=(const DisplayItem&) const;
Мы предлагаем описывать оператор равенства как виртуальный (так как ожидаем, что подклассы могут переопределять его поведение), и описывать оператор неравенства как невиртуальный (так как хотим, чтобы он всегда был логическим отрицанием равенства: подклассам не следует переопределять это).
Аналогичным образом мы можем создавать операторы сравнения объектов типа >= и <=.
Время жизни объектов. Началом времени существования любого объекта является момент его создания (отведение участка памяти), а окончанием - возвращение отведенного участка памяти системе.