Существенно сложнее выполняется поиск нужных функций в языке CLOS, здесь используются дополнительные квалификаторы: : before, : after, : around. Наличие множественного полиморфизма еще более усложняет проблему. При вызове метода в языке CLOS, как правило, реализуется следующий алгоритм:
• Определяется тип аргументов.
• Вычисляется множество допустимых методов.
• Методы сортируются в направлении от наиболее специализированных к более общим.
• Выполняются вызовы всех методов с квалификатором : before.
• Выполняется вызов наиболее специализированного первичного метода.
• Выполняются вызовы всех методов с квалификаторами : after.
• Возвращается значение первичного метода [36].
В CLOS есть протокол для метаобъектов, который позволяет переопределять в том числе и этот алгоритм. На практике, однако, мало кто заходит так далеко. Как справедливо отметили Винстон и Хорн: "Алгоритмы, используемые в языке CLOS, сложны, и даже кудесники программирования стараются не вникать в их детали, так же как физики предпочитают иметь дело с механикой Ньютона, а не с квантовой механикой" [37].
Параллелей между типизацией и наследованием следует ожидать там, где иерархия общего и частного предназначена для выражения смысловых связей между абстракциями. Рассмотрим снова объявления в C++:
TelenetryData telemetry;ElectrycalData electrical(5.0, -5.0, 3.0, 7.0);
Следующий оператор присваивания правомочен:
telemetry = electrical; //electrical - это подтип telemetry
Хотя он формально правилен, он опасен: любые дополнения в состоянии подкласса по сравнению с состоянием суперкласса просто срезаются. Таким образом, дополнительные четыре параметра, определенные в подклассе electrical, будут потеряны при копировании, поскольку их просто некуда записать в объекте telemetry клacca TelemetryData.
Следующий оператор неправилен:
electrical = telemetry; //неправильно: telemetry - это не подтип electrical
Можно сделать заключение, что присвоение объекту y значения объекта x допустимо, если тип объекта x совпадает с типом объекта y или является его подтипом.
В большинстве строго типизированных языков программирования допускается преобразование значений из одного типа в другой, но только в тех случаях, когда между двумя типами существует отношение класс/подкласс. В языке C++ есть оператор явного преобразования, называемый приведением типов. Как правило, такие преобразования используются по отношению к объекту специализированного класса, чтобы присвоить его значение объекту более общего класса. Такое приведение типов считается безопасным, поскольку во время компиляции осуществляется семантический контроль. Иногда необходимы операции приведения объектов более общего класса к специализированным классам. Эти операции не являются надежными с точки зрения строгой типизации, так как во время выполнения программы может возникнуть несоответствие (несовместимость) приводимого объекта с новым типом [Новейшие усовершенствования C++, направленные на динамическое определение типа, смягчили эту проблему]. Однако такие преобразования достаточно часто используются в тех случаях, когда программист хорошо представляет себе все типы объектов. Например, если нет параметризованных типов, часто создаются классы set или bag, представляющие собой наборы произвольных объектов. Их определяют для некоторого базового класса (это гораздо безопаснее, чем использовать идиому void*, как мы делали, определяя класс Queue). Итерационные операции, определенные для такого класса, умеют возвращать только объекты этого базового класса. Внутри конкретного приложения разработчик может использовать этот класс, создавая объекты только какого-то специализированного подкласса, и, зная, что именно он собирается помещать в этот класс, может написать соответствующий преобразователь. Но вся эта стройная конструкция рухнет во время выполнения, если в наборе встретится какой-либо объект неожиданного типа.
Большинство сильно типизированных языков позволяют приложениям оптимизировать технику вызова методов, зачастую сводя пересылку сообщения к простому вызову процедуры. Если, как в C++, иерархия типов совпадает с иерархией классов, такая оптимизация очевидна. Но у нее есть недостатки. Изменение структуры или поведения какого-нибудь суперкласса может поставить вне закона его подклассы. Вот что об этом пишет Микаллеф: "Если правила образования типов основаны на наследовании и мы переделываем какой-нибудь класс так, что меняется его положение в иерархии наследования, клиенты этого класса могут оказаться вне закона с точки зрения типов, несмотря на то, что внешний интерфейс класса остается прежним" [38].
Тем самым мы подходим к фундаментальным вопросам наследования. Как было сказано выше, наследование используется в связи с тем, что у объектов есть что-то общее или между ними есть смысловая ассоциация. Выражая ту же мысль иными словами, Снайдерс пишет: "наследование можно рассматривать, как способ управления повторным использованием программ, то есть, как простое решение разработчика о заимствовании полезного кода. В этом случае механика наследования должна быть гибкой и легко перестраиваемой. Другая точка зрения: наследование отражает принципиальную родственность абстракций, которую невозможно отменить" [39]. В Smalltalk и CLOS эти два аспекта неразделимы. C++ более гибок. В частности, при определении класса его суперкласс можно объявить public (как ElectricalData в нашем примере). В этом случае подкласс считается также и подтипом, то есть обязуется выполнять все обязательства суперкласса, в частности обеспечивая совместимое с суперклассом подмножество интерфейса и обладая неразличимым с точки зрения клиентов суперкласса поведением. Но если при определении класса объявить его суперкласс как private, это будет означать, что, наследуя структуру и поведение суперкласса, подкласс уже не будет его подтипом [Мы можем также объявить суперкласс защищенным, что даст ту же семантику, что и в случае закрытого суперкласса, но открытые и защищенные элементы такого суперкласса будут доступны подклассам]. Это означает, что открытые и защищенные члены суперкласса станут закрытыми членами подкласса, и следовательно они будут недоступны подклассам более низкого уровня. Кроме того, тот факт, что подкласс не будет подтипом, означает, что класс и суперкласс обладают несовместимыми (вообще говоря) интерфейсами с точки зрения клиента. Определим новый класс:
class InternalElectricalData: private ElectricalData {public:
InternalElectricalData(float v1, float v2, float a1, float a2);virtual ~InternalElectricalData();ElectricalData::currentPower;
};
Здесь суперкласс ElectricalData объявлен закрытым. Следовательно, его методы, такие, например, как transmit, недоступны клиентам. Поскольку класс InternalElectricalData не является подтипом ElectricalData, мы уже не сможем присваивать экземпляры подкласса объектам суперкласса, как в случае объявления суперкласса в качестве открытого. Отметим, что функция currentPower сделана видимой путем ее явной квалификации. Иначе она осталась бы закрытой. Как можно было ожидать, правила C++ запрещают делать унаследованный элемент в подклассе "более открытым", чем в суперклассе. Так, член timeStamp, объявленный в классе TelemetryData защищенным, не может быть сделан в подклассе открытым путем явного упоминания (как это было сделано для функции currentpower).
В языке Ada для достижения аналогичного эффекта вместо подтипов используется механизм производных типов. Определение подтипа означает не появление нового типа, а лишь ограничение существующего. А вот определение производного типа создает самостоятельный новый тип, который имеет структуру, заимствованную у исходного типа.
В следующем разделе мы покажем, что наследование с целью повторного использования и агрегация до некоторой степени противоречат друг другу.
Множественное наследование. Мы рассмотрели вопросы, связанные с одиночным наследованием, то есть, когда подкласс имеет ровно один суперкласс. Однако, как указали Влиссидес и Линтон: "одиночное наследование при всей своей полезности часто заставляет программиста выбирать между двумя равно привлекательными классами. Это ограничивает возможность повторного использования предопределенных классов и заставляет дублировать уже имеющиеся коды. Например, нельзя унаследовать графический элемент, который был бы одновременно окружностью и картинкой; приходится наследовать что-то одно и добавлять необходимое от второго" [40].
Множественное наследование прямо поддерживается в языках C++ и CLOS, а также, до некоторой степени, в Smalltalk. Необходимость множественного наследования в OOP остается предметом горячих споров. По нашему опыту, множественное наследование - как парашют: как правило, он не нужен, но, когда вдруг он понадобится, будет жаль, если его не окажется под рукой.
Представьте себе, что нам надо организовать учет различных видов материального и нематериального имущества - банковских счетов, недвижимости, акций и облигаций. Банковские счета бывают текущие и сберегательные. Акции и облигации можно отнести к ценным бумагам, управление ими совершенно отлично от банковских счетов, но и счета и ценные бумаги - это разновидности имущества.
Однако есть много других полезных классификаций тех же видов имущества. В каком-то контексте может потребоваться отличать то, что можно застраховать (недвижимость и, до некоторой степени, сберегательные вклады). Другой аспект - способность имущества приносить дивиденды; это общее свойство банковских счетов и ценных бумаг.
Очевидно, одиночное наследование в данном случае не отражает реальности, так что придется прибегнуть к множественному [В действительности, это - "лакмусовая бумажка" для множественного наследования. Если мы составим структуру классов, в которой конечные классы (листья) могут быть сгруппированы в множества по разным ортогональным признакам (как в нашем примере, где такими признаками были способность приносить дивиденды и возможность страховки) и эти множества перекрываются, то это служит признаком невозможности обойтись одной структурой наследования, в которой бы существовали какие-то промежуточные классы с нужным поведением. Мы можем исправить ситуацию, используя множественное наследование, чтобы соединить два нужных поведения там, где это необходимо]. Получившаяся структура классов показана на рис. 3-7. На нем класс Security (ценные бумаги) наследует одновременно от классов InterestBearingItem (источник дивидендов) и Asset (имущество). Сходным образом, BankAccount (банковский счет) наследует сразу от трех классов: InsurableItem (страхуемое) и уже известным Asset и InterestBearingItem.
Вот как это выражается на C++. Сначала базовые классы:
class Asset ... class InsurableItem ... class InterestBearingItem ...
Теперь промежуточные классы; каждый наследует от нескольких суперклассов:
class BankAccount: public Asset, public InsurableItem, public InterestBearingItem ... class RealEstate: public Asset, public InsurableItem ... class Security: public Asset, public InterestBearingItem ...
Наконец, листья:
class SavingsAccount: public BankAccount ... class CheckingAccount: public BankAccount ... class Stock: public Security ... class Bond: public Security ...
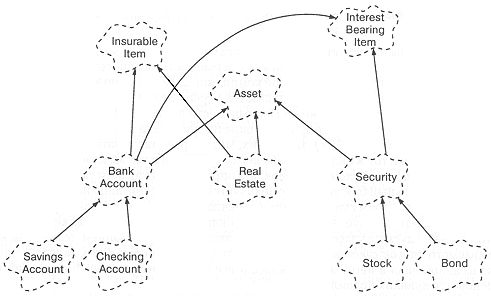
Рис. 3-7. Множественное наследование.
Проектирование структур классов со множественным наследованием - трудная задача, решаемая путем последовательных приближений. Есть две специфические для множественного наследования проблемы - как разрешить конфликты имен между суперклассами и что делать с повторным наследованием.
Конфликт имен происходит, когда в двух или более суперклассах случайно оказывается элемент (переменная или метод) с одинаковым именем. Представьте себе, что как Asset, так и InsurableItem содержат атрибут presentValue, обозначающий текущую стоимость. Так как класс RealEstate наследует обоим этим классам, как понимать наследование двух операций с одним и тем же именем? Это, на самом деле, главная беда множественного наследования: конфликт имен может ввести двусмысленность в поведение класса с несколькими предками.
Борются с этим конфликтом тремя способами. Во-первых, можно считать конфликт имен ошибкой и отвергать его при компиляции (так делают Smalltalk и Eiffel, хотя в Eiffel конфликт можно разрешить, исправив имя). Во-вторых, можно считать, что одинаковые имена означают одинаковый атрибут (так делает CLOS). В третьих, для устранения конфликта разрешается добавить к именам префиксы, указывающие имена классов, откуда они пришли. Такой подход принят в C++ [В C++ конфликт имен элементов подкласса может быть разрешен полной квалификацией имени члена класса. Функции-члены с одинаковыми именами и сигнатурами семантическими считаются идентичными].
О второй проблеме, повторном наследовании, Мейер пишет следующее: "Одно тонкое затруднение при использовании множественного наследования встречается, когда один класс является наследником другого по нескольким линиям. Если в языке разрешено множественное наследование, рано или поздно кто-нибудь напишет класс D, который наследует от B и C, которые, в свою очередь, наследуют от A. Эта ситуация называется повторным наследованием, и с ней нужно корректно обращаться" [41]. Рассмотрим следующий класс:
class MutualFund: public Stock, public Bond ...
который дважды наследует от класса security.
Проблема повторного наследования решается тремя способами. Во-первых, можно его запретить, отслеживая при компиляции. Так сделано в языках Smalltalk и Eiffel (но в Eiffel, опять-таки допускается переименование для устранения неопределенности). Во-вторых, можно явно развести две копии унаследованного элемента, добавляя к именам префиксы в виде имени класса-источника (это один из подходов, принятых в C++). В-третьих, можно рассматривать множественные ссылки на один и тот же класс, как обозначающие один и тот же класс. Так поступают в C++, где повторяющийся суперкласс определяется как виртуальный базовый класс. Виртуальный базовый класс появляется, когда какой-либо подкласс именует другой класс своим суперклассом и отмечает этот суперкласс как виртуальный, чтобы показать, что это - общий (shared) класс. Аналогично, в языке CLOS повторно наследуемые классы "обобществляются" с использованием механизма, называемого список следования классов. Этот список заводят для каждого нового класса, помещая в него сам этот класс и все его суперклассы без повторений на основе следующих правил:
• класс всегда предшествует своему суперклассу;
• каждый класс сам определяет порядок следования своих непосредственных родителей.
В результате граф наследования оказывается плоским, дублирование устраняется, и появляется возможность рассматривать результирующую иерархию как иерархию с одиночным наследованием [43]. Это весьма напоминает топологическую сортировку классов. Если она возможна, то повторное наследование допускается. При этом теоретически могут существовать несколько равноправных результатов сортировки, но алгоритм так или иначе выдает какой-то один из них. Если же сортировка невозможна (например, в структуре возникают циклы), то класс отвергается.
При множественном наследовании часто используется прием создания примесей (mixin). Идея примесей происходит из языка Flavors: можно комбинировать (смешивать) небольшие классы, чтобы строить классы с более сложным поведением. Хендлер пишет об этом так: "примесь синтаксически ничем не отличается от класса, но назначение их разное. Примесь не предназначена для порождения самостоятельно используемых экземпляров - она смешивается с другими классами" [44]. На рис. 3-7 классы InsurableItem и interestBearingItem - это примеси. Ни один из них не может существовать сам по себе, они используются для придания смысла другим классам [Для языка CLOS при обогащении поведения существующих первичных методов обычной практикой является строить примесь, используя только :before- и :after-методы]. Таким образом, примесь - это класс, выражающий не поведение, а одну какую-то хорошо определенную повадку, которую можно привить другим классам через наследование. При этом повадка эта обычно ортогональна собственному поведению наследующего ее класса. Классы, сконструированные целиком из примесей, называют агрегатными.
Множественный полиморфизм. Вернемся к одной из функций-членов класса DisplayItem:
virtual void draw();
Эта операция изображает объект на экране в некотором контексте. Она объявлена виртуальной, то есть полиморфной, переопределяемой подклассами. Когда эту операцию вызывают для какого-то объекта, программа определяет, что, собственно, выполнять (см. врезку выше). Это одиночный полиморфизм в том смысле, что смысл сообщения зависит только от одного параметра, а именно, объекта, для которого вызывается операция.
На самом деле операция draw должна бы зависеть от характеристик используемой системы отображения, в частности от графического режима. Например, в одном случае мы хотим получить изображение с высоким разрешением, а в другом - быстро получить черновое изображение. Можно ввести две различных операции, скажем, drawGraphic и drawText, но это не совсем то, что хотелось бы. Дело в том, что каждый раз, когда требуется учесть новый вид устройства, его надо проводить по всей иерархии надклассов для класса DisplayItem.
В CLOS есть так называемые мультиметоды. Они полиморфны, то есть их смысл зависит от множества параметров (например, от графического режима и от объекта). В C++ мультиметодов нет, поэтому там используется идиома так называемый двойной диспетчеризации.
Например, мы могли бы вести иерархию устройств отображения информации от базового класса DisplayDevice, а атем определить метод класса DisplayItem так:
virtual void draw(DisplayDevice&);
При реализации этого метода мы вызываем графические операции, которые полиморфны относительно переданного параметра типа DisplayItem, таким образом происходит двойная диспетчеризация: draw сначала демонстрирует полиморфное поведение в зависимости от того, к какому подклассу класса DisplayItem принадлежит объект, а затем полиморфизм проявляется в зависимости от того, к какому подклассу класса DisplayDevice принадлежит аргумент. Эту идиому можно продолжить до множественной диспетчеризации.