Английский математик Алан Тьюринг (1912–1954) разработал тест, теперь носящий его имя, который основан на способности компьютера вести беседу на человеческом языке с помощью письменных сообщений. Тьюринг полагал, что в языке отражается весь человеческий разум и что никакая машина не сможет пройти тест, просто овладев языковыми приемами. Хотя в тесте используется письменная речь, Тьюринг считал, что машина смогла бы пройти его лишь при условии, что будет обладать разумом, эквивалентным разуму человека. Критики утверждали, что истинный тест на наличие у машины "человеческого" разума должен включать в себя также зрительную и слуховую компоненты. Поскольку многие из созданных мной систем ИИ обучают компьютер воспринимать и обрабатывать человеческую речь, форму букв и музыкальные звуки, возможно, вы предполагаете, что я встану на защиту этой более полной версии теста для оценки интеллекта. Однако я согласен с тем, что исходной версии теста Тьюринга вполне достаточно - добавление зрительных или слуховых сигналов на входе или на выходе на самом деле совсем не усложняет прохождение теста.
Не нужно быть экспертом в области ИИ, чтобы оценить эффективность Ватсона в игре "Джеопарди!" Хотя я достаточно хорошо понимаю методологию, заложенную в основу действия его ключевых подсистем, это не ослабляет мою эмоциональную реакцию на то, что он (оно?) может делать. Даже полное понимание принципов работы всех подсистем (которого нет ни у кого) не помогает предсказать реакцию Ватсона на конкретную ситуацию. Машина содержит сотни взаимодействующих между собой подсистем, каждая из них одновременно прорабатывает миллионы альтернативных гипотез, так что предсказать ответ всей системы невозможно. Анализ мыслительного процесса, происходящего "в голове" Ватсона за три секунды при ответе на вопрос викторины, у человека занял бы несколько столетий.
Что касается моей собственной истории, в конце 1980-х и в 1990-х гг. мы начали заниматься внедрением систем распознавания человеческой речи в некоторых областях. С одной из наших систем, названной Kurzweil Voice, можно было поговорить о чем угодно, и она могла применяться для редактирования документов. Например, вы могли попросить ее передвинуть в определенное место в тексте третий параграф с предыдущей страницы. В этой ограниченной сфере машина работала достаточно хорошо. Мы также создали систему, обладавшую медицинскими знаниями, которая позволяла врачам диктовать результаты обследования пациентов. Эта машина обладала довольно обширными знаниями в области радиологии и патологии, так что она могла задать врачу вопрос, если что-то в тексте было неясно, и направляла врача по ходу составления отчета. Эта система стала основой многомиллиардного бизнеса компании Nuance.
Понимание естественной речи, особенно в качестве приложения к автоматическим системам распознавания речи, теперь стало элементом серийной продукции. В то время, когда я писал эту книгу, автоматизированный персональный помощник Сири, установленный на модели айфона 4S, произвел фурор в мире сотовых телефонов. Вы можете спросить или попросить Сири практически обо всем, что должен знать и уметь каждый уважающий себя смартфон, например: "Где здесь поблизости индийский ресторан?", или "Сообщи моей жене, что я уже иду", или "Что думают люди о новом фильме Брэда Питта?" - и практически всегда Сири исполняет поручение. Сири может в некоторой степени поддерживать беседу на общие темы. Если вы спросите ее, в чем заключается смысл жизни, она ответит: "42". Поклонники фильма "Автостопом по галактике" знают, что это "ответ на главный вопрос о жизни, вселенной и всяком таком". На вопросы на знание (включая вопрос о смысле жизни) может ответить описанная ниже программа Wolfram Alpha. Существует уже целый мир "чат-ботов", которые нужны только для того, чтобы болтать. Если вы захотите поболтать с нашим чат-ботом по имени Рамона, зайдите на сайт KurzweilAI.net и кликните по ссылке Chat with Ramona.
Люди иногда жалуются, что Сири не может ответить на некоторые вопросы, но обычно это те же самые люди, что частенько недовольны и человеческим сервисом. Иногда я предлагаю решить вопрос совместными усилиями, и часто результат бывает лучше, чем они ожидали. Эти жалобы напоминают мне анекдот о собаке, которая играет в шахматы. На вопрос недоверчивого зрителя владелец собаки отвечает: "Да, это правда, она умеет играть, но слаба в эндшпиле". Тот факт, что широкая публика имеет возможность общаться со своими карманными компьютерами на разговорном языке, открывает новую эпоху. Очень часто люди недооценивают значение технологии первого поколения из-за ее ограничений. Но через несколько лет, когда технология уже хорошо работает, люди по-прежнему не признают ее значение, поскольку теперь она уже не нова. Поэтому следует сказать, что для продукта первого поколения Сири работает очень хорошо и, очевидно, будет работать еще лучше.
Сири использует технологию распознавания речи на основе иерархических моделей Маркова, разработанную компанией Nuance. Расширения для использования разговорной речи впервые были созданы в рамках проекта CALO, финансированного агентством DARPA. Сири снабжена собственной технологией компании Nuance, кроме того, компания предлагает очень похожую технологию под названием Dragon Go.
Методы, используемые для понимания разговорной речи, очень напоминают иерархические скрытые модели Маркова, да и сами ИСММ часто применяются для данных приложений. Хотя иногда в подобных системах не указано, что они используют скрытые модели Маркова или иерархические скрытые модели Маркова, математические основы их функционирования практически идентичны. Все эти системы применяют иерархию линейных последовательностей, каждый элемент которых имеет вес, контакты самостоятельно адаптируются, а вся система в целом самостоятельно организуется в процессе обучения. Обычно обучение продолжается постоянно на протяжении всего времени работы системы. Этот подход отражает иерархическую структуру разговорного языка - это естественное восхождение по понятийной иерархической лестнице от звуков к словам и далее к словосочетаниям и сложным речевым построениям. Имеет смысл применять ГА для параметров, контролирующих конкретный алгоритм обучения в таких классах иерархических систем, и находить оптимальные элементы алгоритма.
За последнее десятилетие возникли новые способы создания подобных иерархических структур. В 1984 г. Дуглас Ленат начал реализацию проекта Cyc (от enCYClopedic) с целью разработки правил кодирования "бытовых знаний". Эти правила были организованы в виде сложной иерархической структуры, и каждое правило, опять же, включало в себя линейную последовательность утверждений. Например, одно такое утверждение может информировать, что у собаки есть лицо (морда). Далее Cyc выводит более общее правило о структуре лиц: на лице есть два глаза, нос и рот и т. д. Нам не нужно иметь отдельное правило для описания собачьей морды и отдельное - для кошачьей, но мы, конечно же, можем создать дополнительное правило, описывающее различие между кошачьей и собачьей мордой. В системе также реализуется следственный механизм: если есть правила, утверждающие, что кокер-спаниель - собака, что собака - животное и что животные потребляют пищу, то на вопрос, питается ли кокер-спаниель, система ответит утвердительно. За прошедшие с тех пор три десятилетия были затрачены тысячи человеко-лет трудов и написано и проверено более миллиона таких утверждений. Интересно, что язык, на котором пишут правила для Cyc (его называют CycL), практически идентичен языку ЛИСП.
Тем временем приверженцы альтернативной теории мыслительного процесса считают, что наилучший подход к пониманию разговорной речи и вообще к созданию разумных систем заключается в автоматизированном обучении системы на многочисленных примерах понятий и явлений. Мощный пример системы такого рода - программа-переводчик Google Translate, которая способна переводить с 50 языков на 50 языков. Это подразумевает 2500 направлений перевода, хотя в большинстве пар языков программа не переводит напрямую с первого языка на второй, а переводит сначала с первого языка на английский, а уже с него на второй язык. Это приводит к сокращению числа направлений перевода всего до 98 (и еще небольшого числа языковых пар, в которых перевод осуществляется напрямую). Данная программа перевода не использует грамматических правил, а создает обширные базы данных для всех пар на основе переведенных документов из программного продукта Rosetta stone ("Розеттский камень"). Для шести официальных языков ООН Google использует документы ООН, поскольку они всегда публикуются на шести языках. Для других языков применяются другие источники.
Результаты такой работы бывают весьма впечатляющими. DARPA организует ежегодные соревнования для выявления лучших автоматических систем перевода для различных пар языков, и Google Translate часто выигрывает эти соревнования для определенных пар, превосходя системы, напрямую разработанные лингвистами.
За последнее десятилетие было сделано два важных открытия, которые в значительной степени повлияли на развитие систем понимания разговорной речи. Первое имеет отношение к иерархическому строению систем. Несмотря на то что подход Google заключается в поиске ассоциаций между линейными последовательностями слов в разных языках, иерархическая структура языка неизбежно влияет на этот процесс. Системы, применяющие метод иерархического обучения (такие как иерархические скрытые модели Маркова), обеспечивают гораздо более высокую эффективность. Однако создание таких систем - далеко не автоматический процесс. Что верно для людей, которые за один раз осваивают один иерархический уровень понятий, то верно и для компьютеров, так что процессом обучения необходимо тщательно руководить.
Другое открытие заключается в том, что для усвоения основного массива знаний хорошо работают правила, сформулированные людьми. Для перевода коротких фрагментов текста такой подход часто обеспечивает более точный результат. Например, DARPA выше оценило переводы коротких текстов с помощью китайско-русского словаря, основанного на правилах, чем переводы Google Translate. Что же касается других элементов языка, к которым относятся миллионы редких фраз и заключенных в них понятий, тут точность переводов, основанных на правилах, непозволительно низкая. Если построить график точности понимания разговорной речи от количества данных, на которых обучалась система, системы, основанные на правилах, сначала показывают более высокую эффективность, но точность распознавания не поднимается выше 70 %. Напротив, статистические системы достигают точности 90 %, но для этого им нужно "изучить" очень большой массив данных.
Часто нам требуется обеспечить приемлемую эффективность при небольшом объеме обучающих данных, но предусмотреть повышение точности при дополнительных тренировках системы. Быстрое достижение средней эффективности позволяет перейти к автоматическому режиму сбора тренировочных данных при каждом использовании. Таким образом, в процессе применения системы происходит и ее обучение, что приводит к постепенному повышению точности результатов. Такое статистическое обучение должно быть полностью основано на принципе иерархии, что отражает структуру языка и принцип работы человеческого мозга.
Именно так работают Сири и Dragon Go: для определения наиболее общих и надежных явлений используются заранее сформулированные правила, а усвоение более редких элементов языка находится в руках конкретных пользователей. Когда создатели Cyc обнаружили, что достигли потолка эффективности при обучении системы на заранее сформулированных правилах, они также переключились на этот подход. Правила, определенные лингвистами, выполняют две важнейшие функции. Во-первых, они обеспечивают приемлемую начальную точность, так что систему можно допускать к широкому использованию, где она будет улучшаться автоматически. Во-вторых, они служат надежной основой для низших уровней понятий, от которых начинается автоматический подъем на более высокие иерархические уровни.
Как отмечалось выше, Ватсон является удивительным примером реализации комбинированного подхода, в котором сочетается настройка системы по предварительно сформулированным правилам и ее иерархическое статистическое обучение. Для создания системы, способной играть в "Джеопарди!" на разговорном языке, компания IBM объединила несколько лучших программ. С 14 по 16 февраля 2011 г. Ватсон соревновался с двумя ведущими игроками: Брэдом Раттером, выигравшим в эту викторину больше денег, чем кто-либо другой, и Кеном Дженнингсом, который удерживал звание чемпиона викторины рекордное время - 75 дней.
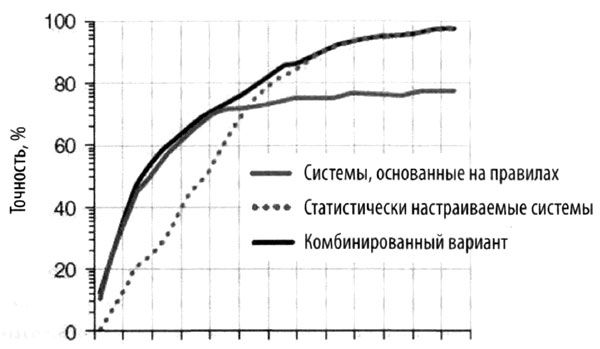
Точность систем распознавания разговорной речи как функция объема тренировочных данных. Наилучшие результаты получаются при сочетании заранее сформулированных правил для освоения "основного" языка и самостоятельной тренировки для освоения "деталей".
В моей первой книге "Эра разумных машин", написанной в середине 1980-х гг., я предсказывал, что компьютер станет чемпионом мира по шахматам примерно к 1998 г. Еще я предсказал, что если это произойдет, то мы либо станем хуже думать о человеческом разуме, либо лучше думать о разуме машин, либо потеряем интерес к шахматам. И если принять во внимание историю, скорее всего, должно было произойти последнее. Так и вышло. В 1997 г., когда суперкомпьютер IBM Deep Blue обыграл чемпиона мира по шахматам Гарри Каспарова, мы немедленно стали утверждать, что именно так и должно было случиться, поскольку компьютеры - логические машины, а шахматы, в конце концов, игра на логику. Победу компьютера не сочли ни важным, ни удивительным событием. Многие критики принялись утверждать, что компьютер никогда бы не смог одолеть человеческую речь - со всеми метафорами, сравнениями, каламбурами, двусмысленностями и юмором.
Вот почему Ватсон так много значит: "Джеопарди!" - именно такая сложная и напряженная игра на знание языка. Типичные вопросы викторины содержат непростые обороты человеческой речи. Однако для большинства зрителей, возможно, не очевидно, что Ватсон не только понимает вопросы, заданные в неожиданной и запутанной форме, но большая часть его знаний не была сформирована людьми. Он обзавелся этими знаниями самостоятельно, прочитав 200 млн страниц документов на человеческом языке, включая "Википедию" и другие энциклопедии, что составляет 4 трлн байт информации. Как вы понимаете, "Википедия" написана не на ЛИСП или CycL, а "нормальными" предложениями со всеми присущими языку двусмысленностями и путаницами. При ответе на вопрос викторины Ватсон должен проверить все 4 млрд знаков реферативного материала (конечно, "Джеопарди!" - не вопросы, а загадки, но это техническая сторона дела - по форме это настоящие вопросы). Если Ватсон способен понять вопрос и ответить на него на основании 200 млн страниц текста - и всего за три секунды! - ничто не может помешать подобным машинам прочесть миллиарды имеющихся в Интернете документов. Именно это сейчас и происходит.
Когда в период с 1970-х по 1990-е гг. мы занимались разработкой систем для распознавания знаков и речи и первых систем, понимающих разговорную речь, мы включали в свои программы "эксперта-менеджера". Мы создавали разные системы для решения одной и той же задачи, но в каждом случае использовали несколько иной подход. Некоторые из различий были незначительными, например вариации параметров, контролирующих математику алгоритма обучения. Но некоторые были фундаментальными, например использование предварительно сформулированных правил вместо иерархических статистически обучающихся систем. Эксперт-менеджер представлял собой компьютерную программу, призванную изучить сильные и слабые стороны различных систем путем анализа их эффективности в реальных ситуациях. Оценка производилась по принципу ортогональности, то есть одна система считалась скорее сильной, другая - скорее слабой. Выяснилось, что общая эффективность комбинированных систем с обученным экспертом-менеджером была намного выше, чем у отдельных систем.